KozakConsensus
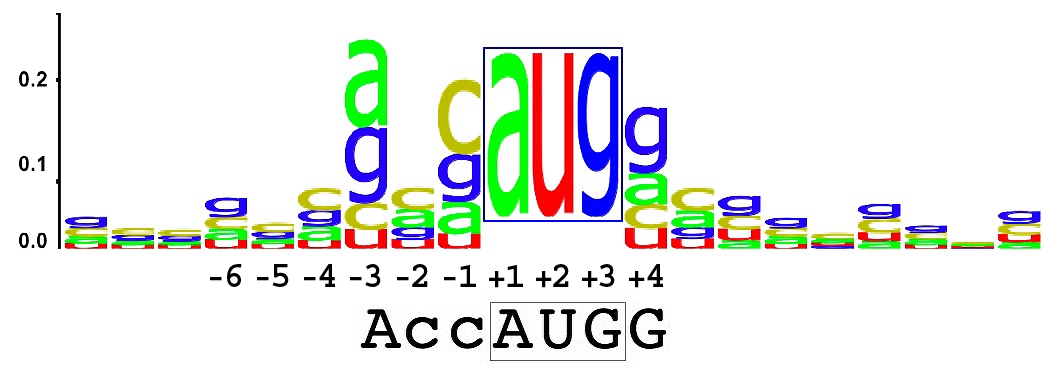
{kind=link}






Relevante Artikel
Kozak-SequenzDie Kozak-Sequenz, auch engl. Kozak consensus sequence genannt, ist eine nach der US-amerikanischen Biochemikerin Marilyn Kozak benannte Nukleinbasen-Sequenz in der Messenger-RNA (mRNA) eukaryotischer Lebewesen. Sie stellt einen Konsens aus den am häufigsten vorkommenden Nukleinbasen in unmittelbarer Nähe des Startcodons AUG auf der mRNA dar. Als Kozak-Sequenz wird oft die Basenfolge (gcc)gccRccATGG genannt, wobei es deutliche Unterschiede zwischen verschiedenen Gruppen von Eukaryoten gibt. Die Kozak-Sequenz oder eine ähnliche Nukleinbasenfolge wird von den Ribosomen erkannt und ist für den Start der Translation im Rahmen der Proteinbiosynthese von Bedeutung. Abweichungen in der Nukleinbasenfolge können Auswirkungen auf die Proteinbiosynthese haben. .. weiterlesen